Launch in Binder ![]()
UK Precipitation¶
February 2020 case study¶
February 2020 was the wettest February on record in the UK (since 1862), according to the Met Office. The UK faced three official storms during February, and this exceptional phenomena attracted media attention, such as an article from the BBC on increased climate concerns among the population.
Here, we will test the applicability and potential of using SEAS5 for estimating the likelihood of the 2020 UK February precipitation event.
Retrieve data¶
The main functions to retrieve all forecasts (SEAS5) is retrieve_SEAS5. We want to download February average precipitation over the UK. By default, the hindcast years of 1981-2016 are downloaded for SEAS5. The folder indicates where the files will be stored, in this case outside of the UNSEEN-open repository, in a ‘UK_example’ directory. For more explanation, see retrieve.
[2]:
import os
import sys
sys.path.insert(0, os.path.abspath('../../../'))
os.chdir(os.path.abspath('../../../'))
import src.cdsretrieve as retrieve
import src.preprocess as preprocess
[29]:
import numpy as np
import xarray as xr
[4]:
retrieve.retrieve_SEAS5(variables = 'total_precipitation',
target_months = [2],
area = [60, -11, 50, 2],
years=np.arange(1981, 2021),
folder = '../UK_example/SEAS5/')
We use the EOBS observational dataset to evaluate the UNSEEN ensemble. I tried to download EOBS through the Copernicus Climate Data Store, but the Product is temporally disabled for maintenance purposes. As workaround I downloaded EOBS (from 1950 - 2019) and the most recent EOBS data (2020) here. Note, you have to register as E-OBS user.
Preprocess¶
In the preprocessing step, we first merge all downloaded files into one xarray dataset, see preprocessing.
[6]:
SEAS5_UK = preprocess.merge_SEAS5(folder = '../UK_example/SEAS5/', target_months = [2])
Lead time: 01
12
11
10
9
The SEAS5 total precipitation rate is in m/s. You can easily convert this and change the attributes. Click on the show/hide attributes button to see the assigned attributes.
[22]:
SEAS5_UK['tprate'] = SEAS5_UK['tprate'] * 1000 * 3600 * 24 ## From m/s to mm/d
SEAS5_UK['tprate'].attrs = {'long_name': 'rainfall',
'units': 'mm/day',
'standard_name': 'thickness_of_rainfall_amount'}
SEAS5_UK
[22]:
- latitude: 11
- leadtime: 5
- longitude: 14
- number: 51
- time: 39
- longitude(longitude)float32-11.0 -10.0 -9.0 ... 0.0 1.0 2.0
- units :
- degrees_east
- long_name :
- longitude
array([-11., -10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0., 1., 2.], dtype=float32) - number(number)int640 1 2 3 4 5 6 ... 45 46 47 48 49 50
- long_name :
- ensemble_member
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - time(time)datetime64[ns]1982-02-01 ... 2020-02-01
- long_name :
- time
array(['1982-02-01T00:00:00.000000000', '1983-02-01T00:00:00.000000000', '1984-02-01T00:00:00.000000000', '1985-02-01T00:00:00.000000000', '1986-02-01T00:00:00.000000000', '1987-02-01T00:00:00.000000000', '1988-02-01T00:00:00.000000000', '1989-02-01T00:00:00.000000000', '1990-02-01T00:00:00.000000000', '1991-02-01T00:00:00.000000000', '1992-02-01T00:00:00.000000000', '1993-02-01T00:00:00.000000000', '1994-02-01T00:00:00.000000000', '1995-02-01T00:00:00.000000000', '1996-02-01T00:00:00.000000000', '1997-02-01T00:00:00.000000000', '1998-02-01T00:00:00.000000000', '1999-02-01T00:00:00.000000000', '2000-02-01T00:00:00.000000000', '2001-02-01T00:00:00.000000000', '2002-02-01T00:00:00.000000000', '2003-02-01T00:00:00.000000000', '2004-02-01T00:00:00.000000000', '2005-02-01T00:00:00.000000000', '2006-02-01T00:00:00.000000000', '2007-02-01T00:00:00.000000000', '2008-02-01T00:00:00.000000000', '2009-02-01T00:00:00.000000000', '2010-02-01T00:00:00.000000000', '2011-02-01T00:00:00.000000000', '2012-02-01T00:00:00.000000000', '2013-02-01T00:00:00.000000000', '2014-02-01T00:00:00.000000000', '2015-02-01T00:00:00.000000000', '2016-02-01T00:00:00.000000000', '2017-02-01T00:00:00.000000000', '2018-02-01T00:00:00.000000000', '2019-02-01T00:00:00.000000000', '2020-02-01T00:00:00.000000000'], dtype='datetime64[ns]') - latitude(latitude)float3260.0 59.0 58.0 ... 52.0 51.0 50.0
- units :
- degrees_north
- long_name :
- latitude
array([60., 59., 58., 57., 56., 55., 54., 53., 52., 51., 50.], dtype=float32)
- leadtime(leadtime)int642 3 4 5 6
array([2, 3, 4, 5, 6])
- tprate(leadtime, time, number, latitude, longitude)float32dask.array<chunksize=(1, 1, 51, 11, 14), meta=np.ndarray>
- long_name :
- rainfall
- units :
- mm/day
- standard_name :
- thickness_of_rainfall_amount
Array Chunk Bytes 6.13 MB 31.42 kB Shape (5, 39, 51, 11, 14) (1, 1, 51, 11, 14) Count 2281 Tasks 195 Chunks Type float32 numpy.ndarray
- Conventions :
- CF-1.6
- history :
- 2020-05-13 14:49:43 GMT by grib_to_netcdf-2.16.0: /opt/ecmwf/eccodes/bin/grib_to_netcdf -S param -o /cache/data7/adaptor.mars.external-1589381366.1540039-11561-3-ad31a097-72e2-45ce-a565-55c62502f358.nc /cache/tmp/ad31a097-72e2-45ce-a565-55c62502f358-adaptor.mars.external-1589381366.1545565-11561-1-tmp.grib
Then I open the EOBS dataset and extract February monthly mean precipitation. I have taken the average mm/day over the month, which is more fair than the total monthly precipitation because of leap days.
[30]:
EOBS = xr.open_dataset('../UK_example/EOBS/rr_ens_mean_0.25deg_reg_v20.0e.nc') ## open the data
EOBS = EOBS.resample(time='1m').mean() ## Monthly averages
EOBS = EOBS.sel(time=EOBS['time.month'] == 2) ## Select only February
EOBS
/soge-home/users/cenv0732/.conda/envs/UNSEEN-open/lib/python3.8/site-packages/xarray/core/nanops.py:142: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis=axis, dtype=dtype)
[30]:
- latitude: 201
- longitude: 464
- time: 70
- time(time)datetime64[ns]1950-02-28 ... 2019-02-28
array(['1950-02-28T00:00:00.000000000', '1951-02-28T00:00:00.000000000', '1952-02-29T00:00:00.000000000', '1953-02-28T00:00:00.000000000', '1954-02-28T00:00:00.000000000', '1955-02-28T00:00:00.000000000', '1956-02-29T00:00:00.000000000', '1957-02-28T00:00:00.000000000', '1958-02-28T00:00:00.000000000', '1959-02-28T00:00:00.000000000', '1960-02-29T00:00:00.000000000', '1961-02-28T00:00:00.000000000', '1962-02-28T00:00:00.000000000', '1963-02-28T00:00:00.000000000', '1964-02-29T00:00:00.000000000', '1965-02-28T00:00:00.000000000', '1966-02-28T00:00:00.000000000', '1967-02-28T00:00:00.000000000', '1968-02-29T00:00:00.000000000', '1969-02-28T00:00:00.000000000', '1970-02-28T00:00:00.000000000', '1971-02-28T00:00:00.000000000', '1972-02-29T00:00:00.000000000', '1973-02-28T00:00:00.000000000', '1974-02-28T00:00:00.000000000', '1975-02-28T00:00:00.000000000', '1976-02-29T00:00:00.000000000', '1977-02-28T00:00:00.000000000', '1978-02-28T00:00:00.000000000', '1979-02-28T00:00:00.000000000', '1980-02-29T00:00:00.000000000', '1981-02-28T00:00:00.000000000', '1982-02-28T00:00:00.000000000', '1983-02-28T00:00:00.000000000', '1984-02-29T00:00:00.000000000', '1985-02-28T00:00:00.000000000', '1986-02-28T00:00:00.000000000', '1987-02-28T00:00:00.000000000', '1988-02-29T00:00:00.000000000', '1989-02-28T00:00:00.000000000', '1990-02-28T00:00:00.000000000', '1991-02-28T00:00:00.000000000', '1992-02-29T00:00:00.000000000', '1993-02-28T00:00:00.000000000', '1994-02-28T00:00:00.000000000', '1995-02-28T00:00:00.000000000', '1996-02-29T00:00:00.000000000', '1997-02-28T00:00:00.000000000', '1998-02-28T00:00:00.000000000', '1999-02-28T00:00:00.000000000', '2000-02-29T00:00:00.000000000', '2001-02-28T00:00:00.000000000', '2002-02-28T00:00:00.000000000', '2003-02-28T00:00:00.000000000', '2004-02-29T00:00:00.000000000', '2005-02-28T00:00:00.000000000', '2006-02-28T00:00:00.000000000', '2007-02-28T00:00:00.000000000', '2008-02-29T00:00:00.000000000', '2009-02-28T00:00:00.000000000', '2010-02-28T00:00:00.000000000', '2011-02-28T00:00:00.000000000', '2012-02-29T00:00:00.000000000', '2013-02-28T00:00:00.000000000', '2014-02-28T00:00:00.000000000', '2015-02-28T00:00:00.000000000', '2016-02-29T00:00:00.000000000', '2017-02-28T00:00:00.000000000', '2018-02-28T00:00:00.000000000', '2019-02-28T00:00:00.000000000'], dtype='datetime64[ns]') - latitude(latitude)float6425.38 25.62 25.88 ... 75.12 75.38
- units :
- degrees_north
- long_name :
- Latitude values
- axis :
- Y
- standard_name :
- latitude
array([25.375, 25.625, 25.875, ..., 74.875, 75.125, 75.375])
- longitude(longitude)float64-40.38 -40.12 ... 75.12 75.38
- units :
- degrees_east
- long_name :
- Longitude values
- axis :
- X
- standard_name :
- longitude
array([-40.375, -40.125, -39.875, ..., 74.875, 75.125, 75.375])
- rr(time, latitude, longitude)float32nan nan nan nan ... nan nan nan nan
array([[[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], ..., [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]]], dtype=float32)
Here I define the attributes, that xarray uses when plotting
[31]:
EOBS['rr'].attrs = {'long_name': 'rainfall', ##Define the name
'units': 'mm/day', ## unit
'standard_name': 'thickness_of_rainfall_amount'} ## original name, not used
EOBS['rr'].mean('time').plot() ## and show the 1950-2019 average February precipitation
/soge-home/users/cenv0732/.conda/envs/UNSEEN-open/lib/python3.8/site-packages/xarray/core/nanops.py:142: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis=axis, dtype=dtype)
[31]:
<matplotlib.collections.QuadMesh at 0x7f93884292b0>

The 2020 data file is separate and needs the same preprocessing:
[32]:
EOBS2020 = xr.open_dataset('../UK_example/EOBS/rr_0.25deg_day_2020_grid_ensmean.nc.1') #open
EOBS2020 = EOBS2020.resample(time='1m').mean() #Monthly mean
EOBS2020['rr'].sel(time='2020-04').plot() #show map
EOBS2020 ## display dataset
/soge-home/users/cenv0732/.conda/envs/UNSEEN-open/lib/python3.8/site-packages/xarray/core/nanops.py:142: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis=axis, dtype=dtype)
[32]:
- latitude: 201
- longitude: 464
- time: 12
- time(time)datetime64[ns]2020-01-31 ... 2020-12-31
array(['2020-01-31T00:00:00.000000000', '2020-02-29T00:00:00.000000000', '2020-03-31T00:00:00.000000000', '2020-04-30T00:00:00.000000000', '2020-05-31T00:00:00.000000000', '2020-06-30T00:00:00.000000000', '2020-07-31T00:00:00.000000000', '2020-08-31T00:00:00.000000000', '2020-09-30T00:00:00.000000000', '2020-10-31T00:00:00.000000000', '2020-11-30T00:00:00.000000000', '2020-12-31T00:00:00.000000000'], dtype='datetime64[ns]') - latitude(latitude)float6425.38 25.62 25.88 ... 75.12 75.38
- standard_name :
- latitude
- long_name :
- Latitude values
- units :
- degrees_north
- axis :
- Y
array([25.375, 25.625, 25.875, ..., 74.875, 75.125, 75.375])
- longitude(longitude)float64-40.38 -40.12 ... 75.12 75.38
- standard_name :
- longitude
- long_name :
- Longitude values
- units :
- degrees_east
- axis :
- X
array([-40.375, -40.125, -39.875, ..., 74.875, 75.125, 75.375])
- rr(time, latitude, longitude)float32nan nan nan nan ... nan nan nan nan
array([[[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], ..., [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]], [[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], ..., [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]]], dtype=float32)

We then extract UK averaged precipitation for SEAS5 and EOBS. We upscale EOBS to the SEAS5 grid and apply the same UK mask to extract the UK average for both datasets. Using EOBS + upscaling shows how to regrid and extract the country average timeseries.
Here, we export the SEAS5 and EOBS datasets as NetCDF files to be imported in the other notebook. Note that for EOBS we had to download two separate files, which we concatenate below before exporting as nc.
[33]:
SEAS5_UK.to_netcdf('../UK_example/SEAS5/SEAS5_UK.nc') ## Store SEAS5 as NetCDF for future import
EOBS_concat = xr.concat([EOBS,EOBS2020.sel(time='2020-02')],dim='time') ## Concatenate the 1950-2019 and 2020 datasets.
EOBS_concat.to_netcdf('../UK_example/EOBS/EOBS_UK.nc') ## And store the 1950-2010 February precipitation into one nc for future import
Evaluate¶
Note
From here onward we use R and not python!
We switch to R since we believe R has a better functionality in extreme value statistics.
[1]:
setwd('../../..')
# getwd()
EOBS_UK_weighted_df <- read.csv("Data/EOBS_UK_weighted_upscaled.csv", stringsAsFactors=FALSE)
SEAS5_UK_weighted_df <- read.csv("Data/SEAS5_UK_weighted_masked.csv", stringsAsFactors=FALSE)
## Convert the time class to Date format
EOBS_UK_weighted_df$time <- lubridate::ymd(EOBS_UK_weighted_df$time)
str(EOBS_UK_weighted_df)
EOBS_UK_weighted_df_hindcast <- EOBS_UK_weighted_df[
EOBS_UK_weighted_df$time > '1982-02-01' &
EOBS_UK_weighted_df$time < '2017-02-01',
]
SEAS5_UK_weighted_df$time <- lubridate::ymd(SEAS5_UK_weighted_df$time)
str(SEAS5_UK_weighted_df)
'data.frame': 71 obs. of 2 variables:
$ time: Date, format: "1950-02-28" "1951-02-28" ...
$ rr : num 4.13 3.25 1.07 1.59 2.59 ...
'data.frame': 9945 obs. of 4 variables:
$ leadtime: int 2 2 2 2 2 2 2 2 2 2 ...
$ number : int 0 0 0 0 0 0 0 0 0 0 ...
$ time : Date, format: "1982-02-01" "1983-02-01" ...
$ tprate : num 1.62 2.93 3.27 2 3.31 ...
Is the UNSEEN ensemble realistic?
[2]:
require(UNSEEN)
require(ggplot2)
require(ggpubr)
Loading required package: UNSEEN
Loading required package: ggplot2
Warning message:
“replacing previous import ‘vctrs::data_frame’ by ‘tibble::data_frame’ when loading ‘dplyr’”
Loading required package: ggpubr
Timeseries¶
We plot the timeseries of SEAS5 (UNSEEN) and EOBS (OBS) for UK February precipitation.
[3]:
unseen_timeseries(ensemble = SEAS5_UK_weighted_df,
obs = EOBS_UK_weighted_df[EOBS_UK_weighted_df$time > '1982-02-01',],
ylab = 'UK February precipitation (mm/d)') +
theme(text = element_text(size = 14)) #This is just to increase the figure font
Warning message:
“Removed 4654 rows containing non-finite values (stat_boxplot).”
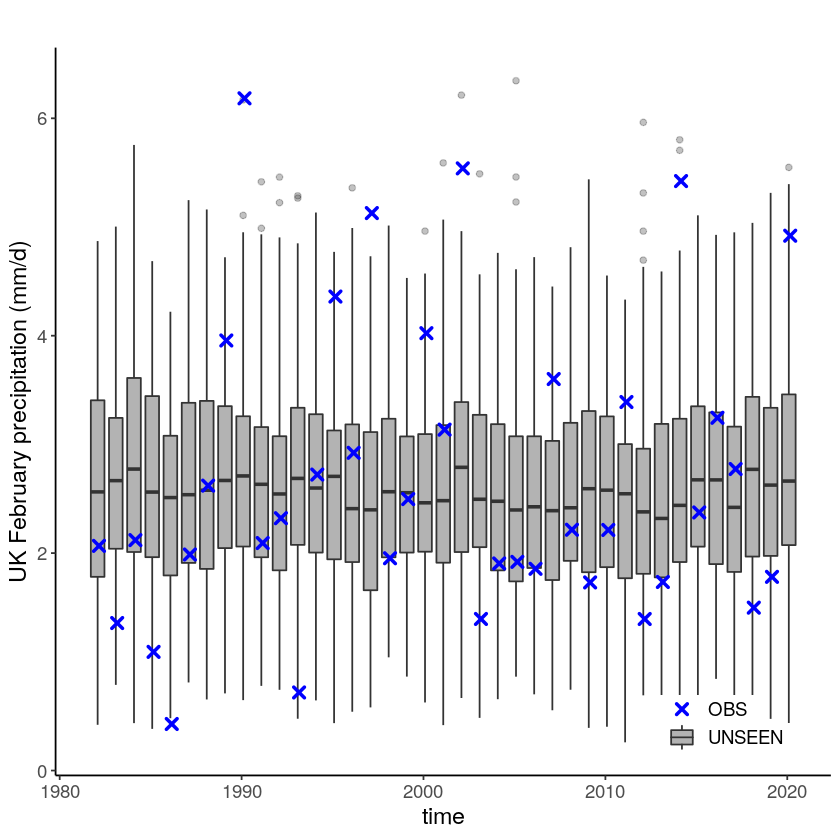
We select the timeseries for the hindcast years 1981-2016.
[4]:
SEAS5_UK_hindcast <- SEAS5_UK_weighted_df[
SEAS5_UK_weighted_df$time < '2017-02-01' &
SEAS5_UK_weighted_df$number < 25,]
[5]:
unseen_timeseries(ensemble = SEAS5_UK_hindcast,
obs = EOBS_UK_weighted_df_hindcast,
ylab = 'UK February precipitation (mm/d)')# %>%
# ggsave(height = 5, width = 6, filename = "graphs/UK_timeseries.png")
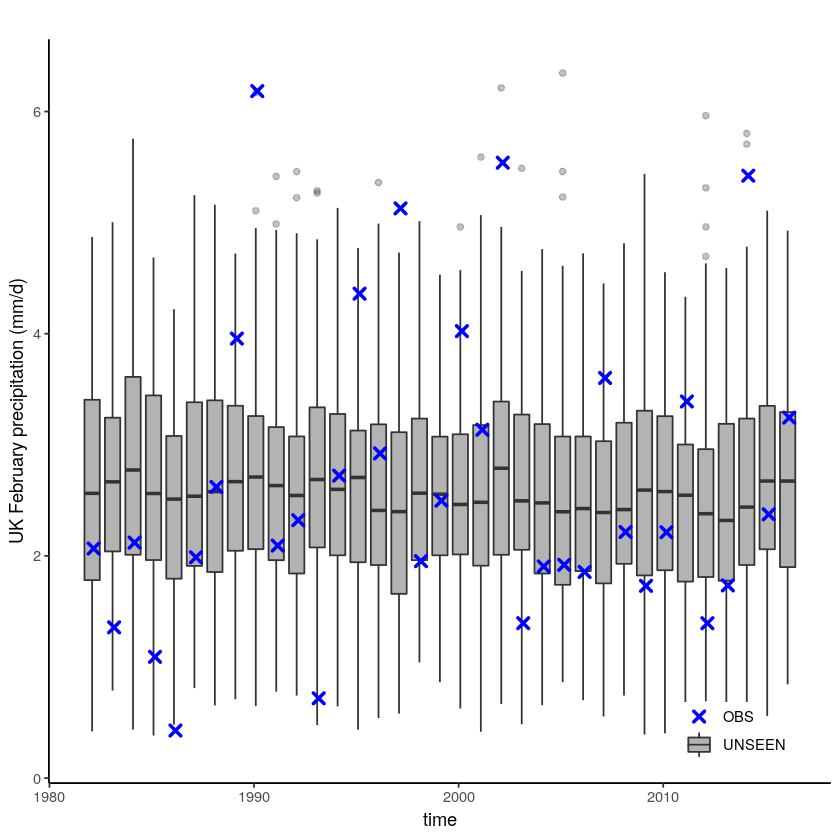
Evaluation tests¶
With the hindcast dataset we evaluate the independence, stability and fidelity.
First the independence test. This test checks if the forecasts are independent. If they are not, the event are not unique and care should be taken in the extreme value analysis. Because of the chaotic behaviour of the atmosphere, independence of precipitation events is expected beyond a lead time of two weeks. Here we use lead times 2-6 months and find that the boxplots are within the expected range (perhaps very small dependence in lead time 2). More info in our paper: https://doi.org/10.1038/s41612-020-00149-4.
[6]:
Independence_UK = independence_test(ensemble = SEAS5_UK_hindcast,
detrend = TRUE) +
theme(text = element_text(size = 14))
Independence_UK
Warning message:
“Removed 1625 rows containing non-finite values (stat_ydensity).”
Warning message:
“Removed 1625 rows containing non-finite values (stat_boxplot).”
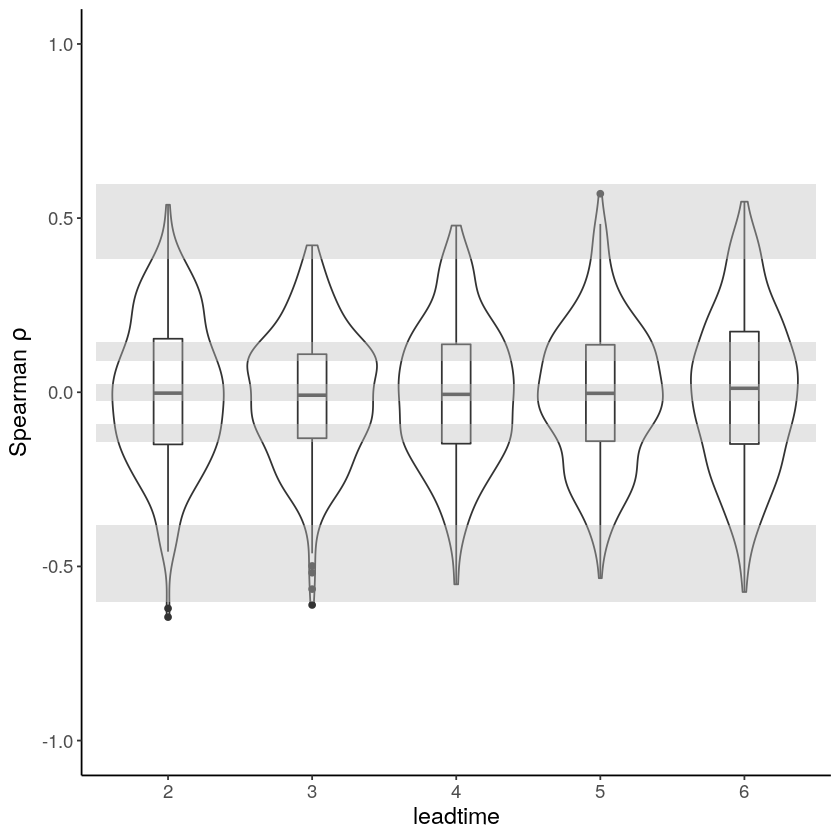
The test for model stability: Is there a drift in the simulated precipitation over lead times?
We find that the model is stable for UK February precipitation.
[7]:
Stability_UK = stability_test(ensemble = SEAS5_UK_hindcast,
lab = 'UK February precipitation (mm/d)')
Stability_UK
Warning message:
“Removed 4 row(s) containing missing values (geom_path).”
The fidelity test shows us how consistent the model simulations of UNSEEN (SEAS5) are with the observed (EOBS). With this test we can asses systematic biases. The UNSEEN dataset is much larger than the observed – hence they cannot simply be compared. For example, what if we had faced a few more or a few less precipitation extremes purely by chance?
This would influence the observed mean, but not so much influence the UNSEEN ensemble because of the large data sample. Therefore we express the UNSEEN ensemble as a range of plausible means, for data samples of the same length as the observed. We do the same for higher order statistical moments.
[8]:
Fidelity_UK = fidelity_test(obs = EOBS_UK_weighted_df_hindcast$rr,
ensemble = SEAS5_UK_hindcast$tprate,
fontsize = 14
)
Fidelity_UK
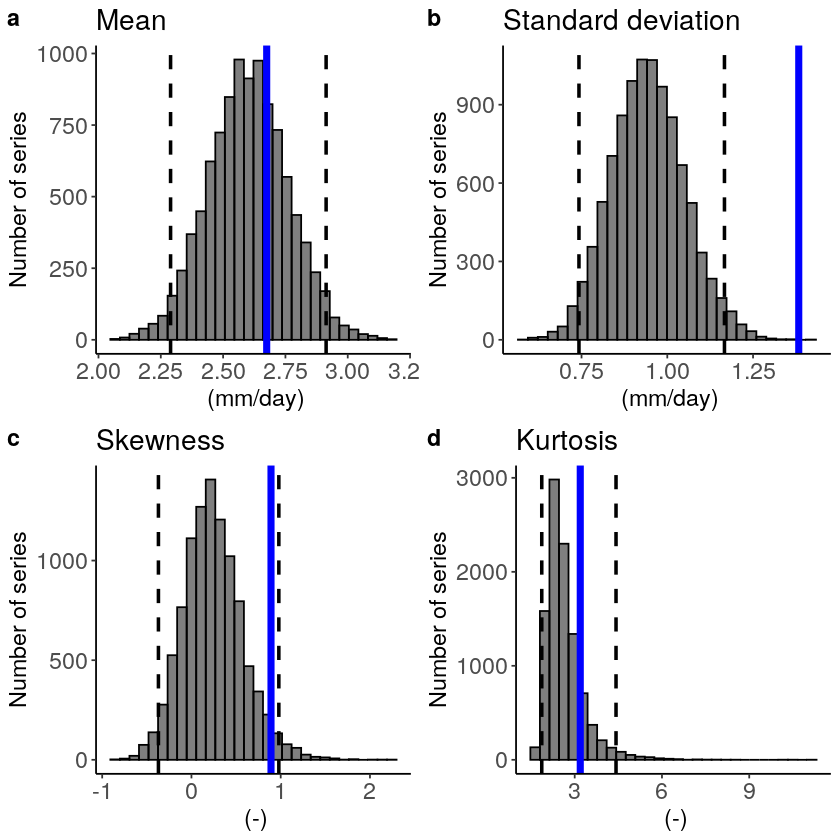
We find that the standard deviation within the model (the grey histograms and lines) are too low compared to the observed.
We can include a simple mean-bias correction (ratio) in this plot by setting biascor = TRUE. However, in this case it won’t help:
[16]:
fidelity_test(obs = EOBS_UK_weighted_df_hindcast$rr,
ensemble = SEAS5_UK_hindcast$tprate,
biascor = TRUE
)
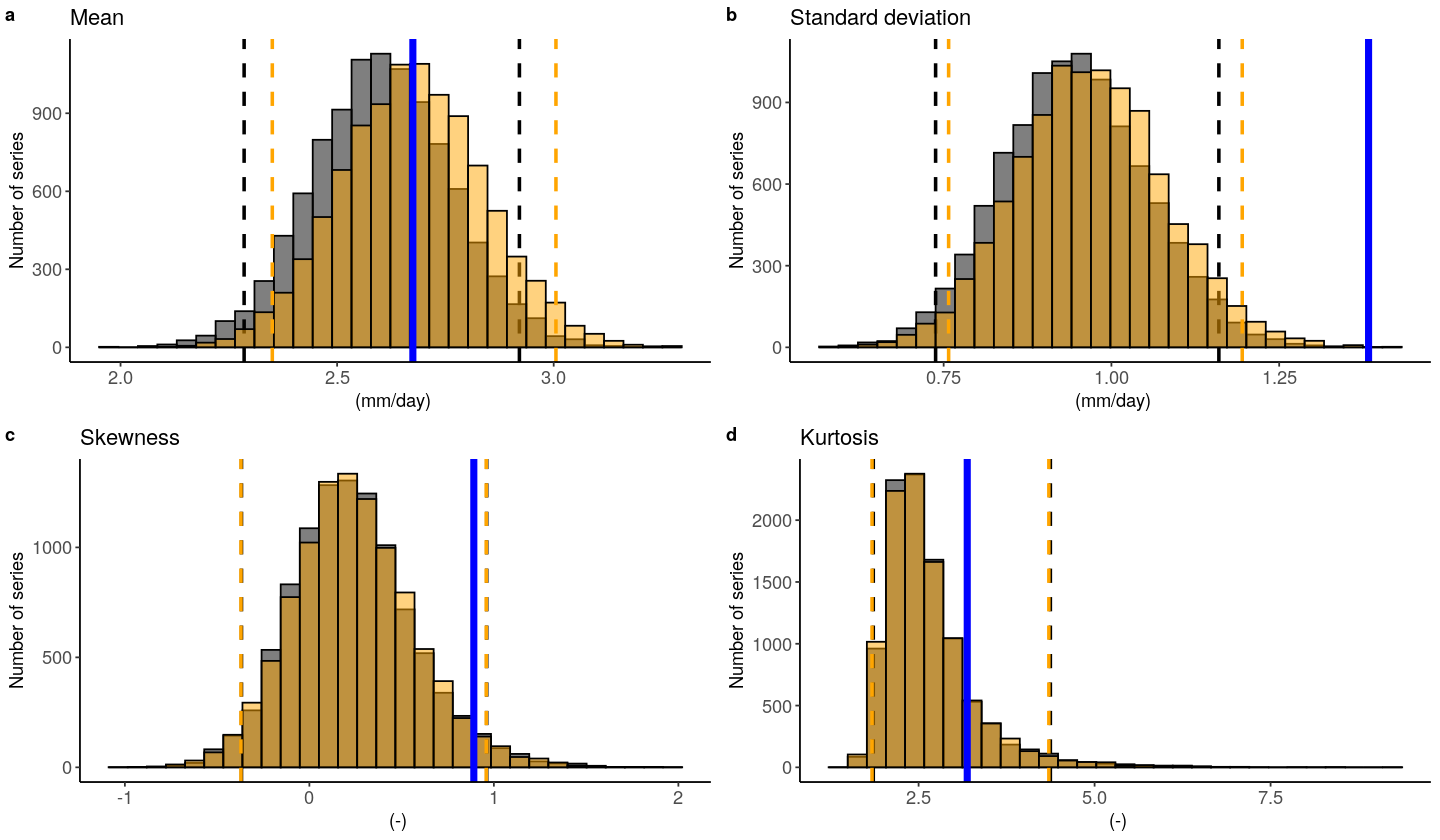
Check the documentation of the test ?fidelity_test
Illustrate¶
First, we fit a Gumbel and a GEV distribution (including shape parameter) to the observed extremes. The Gumbel distribution best describes the data because the p-value of 0.9 is much above 0.05 (based on the likelihood ratio test).
[9]:
fit_obs_Gumbel <- fevd(x = EOBS_UK_weighted_df_hindcast$rr,
type = "Gumbel"
)
fit_obs_GEV <- fevd(x = EOBS_UK_weighted_df_hindcast$rr,
type = "GEV"
)
lr.test(fit_obs_Gumbel, fit_obs_GEV)
Likelihood-ratio Test
data: EOBS_UK_weighted_df_hindcast$rrEOBS_UK_weighted_df_hindcast$rr
Likelihood-ratio = 0.014629, chi-square critical value = 3.8415, alpha
= 0.0500, Degrees of Freedom = 1.0000, p-value = 0.9037
alternative hypothesis: greater
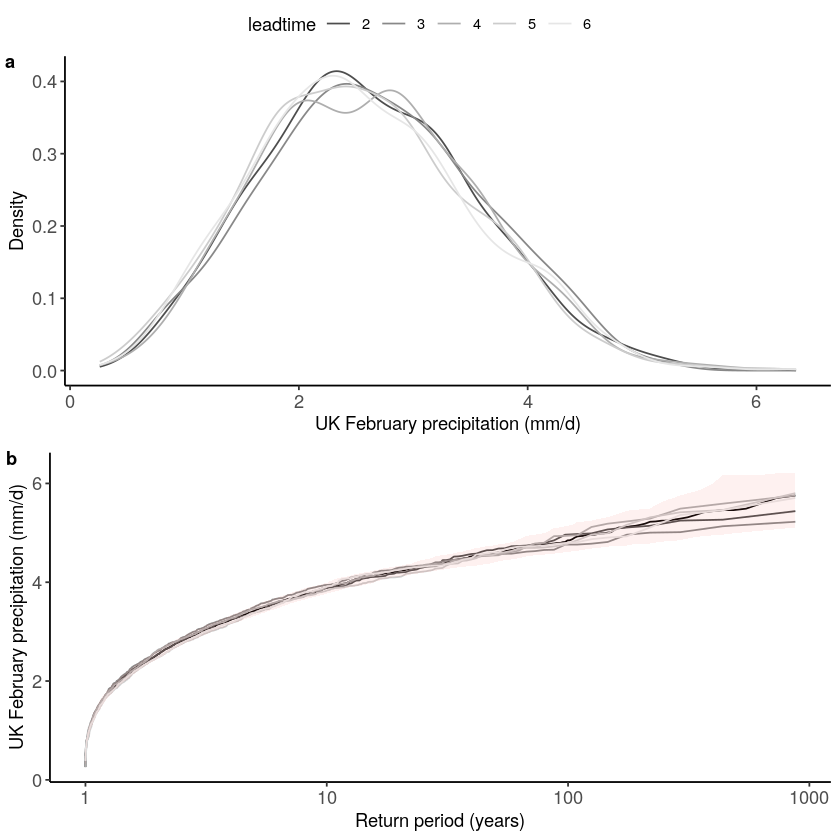
We show the gumbel plot for the observed (EOBS) and UNSEEN (SEAS5 hindcast data). This shows that the UNSEEN simulations are not within the uncertainty range of the observations. This has to do with the variability of the model that is too low, as indicated in the evaluation section. The EVT_plot function was written for this case study, but we cannot ensure robustness to other case studies.
[14]:
source('src/evt_plot.r')
options(repr.plot.width = 12)
EVT_plot(ensemble = SEAS5_UK_hindcast$tprate,
obs = EOBS_UK_weighted_df_hindcast$rr,
main = "1981-2016",
GEV_type = "Gumbel",
# ylim = 3,
y_lab = 'UK February precipitation (mm/d)'
)
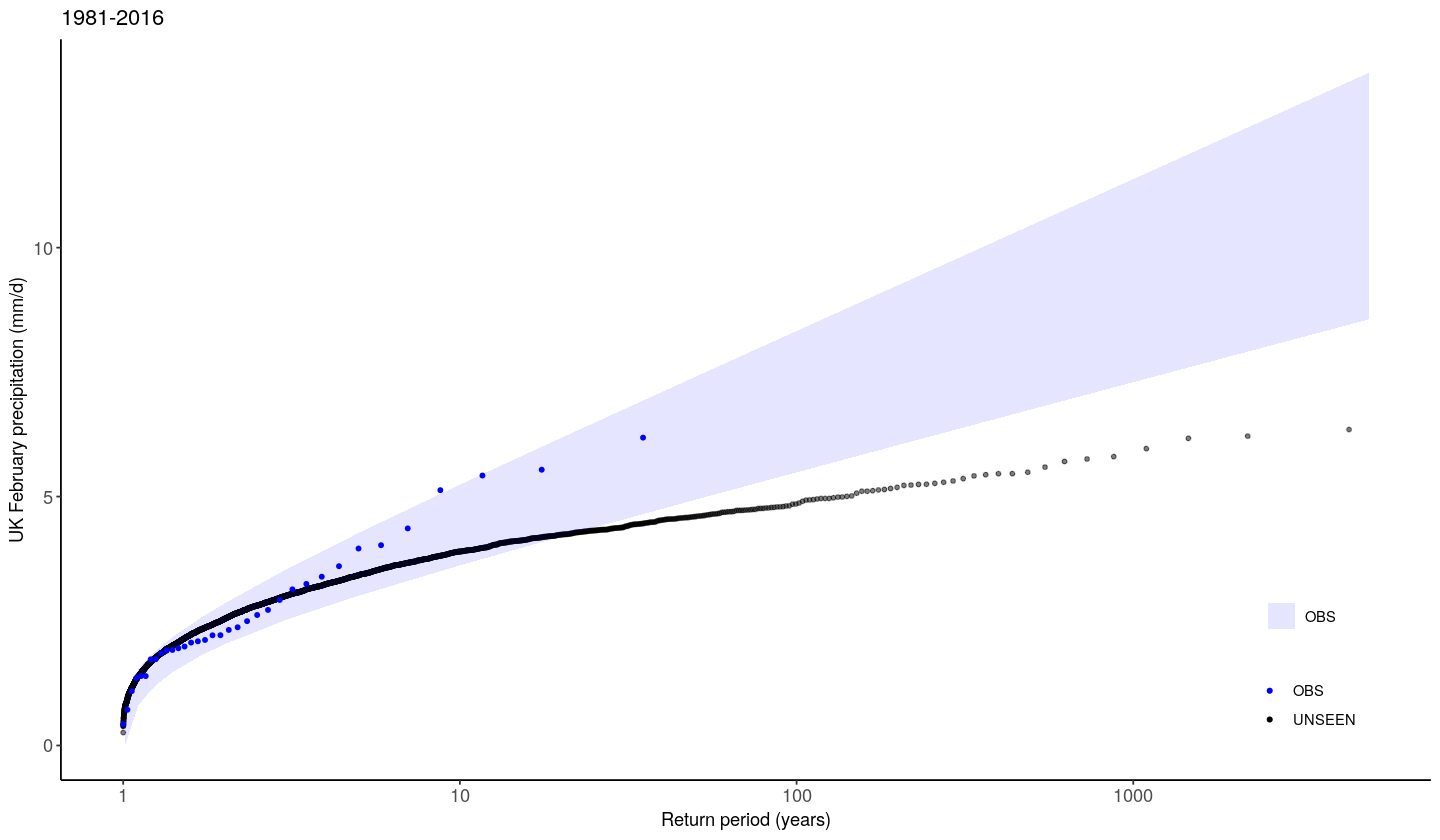
Potential¶
We find that there is there too little variability within SEAS5 hindcasts of UK february precipitation. It might be resolution dependent or related to the signal-to-noise that is a problem over this region. The results can be fed back to model developers to help improve the models.
The use of other observational datasets and other model simulations can be further explored. For example, the UK Met Office studied UK monthly precipitation extremes using the UNSEEN method (Thompson et al., 2017). They showed that monthly precipitation records for south east England have a 7% chance of being exceeded in at least one month in any given winter. Their work was taken up in the UK National Flood Resilience Review (2016), showing the high relevance of the method.