What is UNSEEN?¶
The UNprecedented Simulated Extremes using ENsembles (UNSEEN, Thompson et al., 2017) approach uses forecast ensemble members to compute robust statistics for rare events, which is challenging to compute from historical records. UNSEEN may therefore help to identify plausible – yet unseen – weather extremes and to stress-test adaptation measures with maximum credible events. For more info about UNSEEN, see our preprint, BOX A in particular.
We believe UNSEEN has large potential as a tool to inform decision-making about unforeseen hydro-climatic risks. In order to apply UNSEEN: 1. Model ensemble members must be applicable for generating large samples of weather events (see Box B in paper); and 2. Large volumes of data must be handled.
Our paper presents a 6-step protocol (see below) and, as part of the protocol, the UNSEEN-open workflow, to guide users in applying UNSEEN more generally. The paper discusses the protocol in detail, including the practicalities of the workflow and its potential application to other datasets. The technical steps and relevant code are documented here. The protocol is applicable to any prediction system, whilst the code and guidance for UNSEEN-open is developed to work with the Copernicus Data Store (CDS, https://cds.climate.copernicus.eu/).
UNSEEN-open¶
In this project, the aim is to build an open, reproducible, and transferable workflow for UNSEEN.
This means that we aim for anyone to be able to assess any climate extreme event anywhere in the world!
UNSEEN-open was therefore developed with a focus on Copernicus SEAS5 forecasts, because it is an openly available, stable, homogeneous, global, high-resolution, large ensemble with continuous evaluation at ECMWF. We refer to section 4.2 of our paper for a discussion of other relevant datasets.
All code showing how UNSEEN data can be handled is documented on Jupyter notebooks. This means that some familiarity with python and R is (currently) required. Future further developments of tools and applications that do not require coding by the user themselves would be very interesting if time and funding allows!
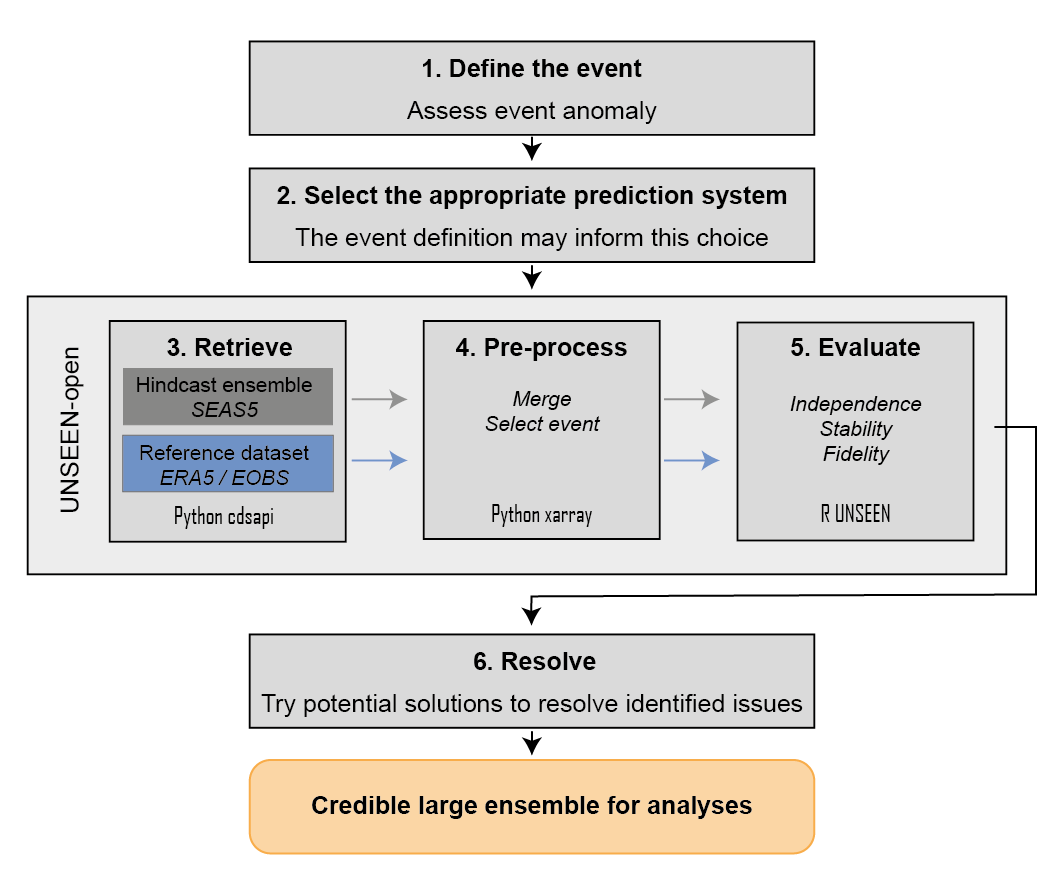
Overview¶
Here we provide an overview of steps 3-5 for UNSEEN-open.
Retrieve¶
We use global open Copernicus C3S data: the seasonal prediction system SEAS5 and the reanlysis ERA5.
The functions to retrieve all forecasts (SEAS5) and reanalysis (ERA5) are retrieve_SEAS5 and retrieve_ERA5. You can select the climate variable, the target month(s) and the area - for more explanation see retrieve.
[2]:
retrieve.retrieve_SEAS5(
variables=['2m_temperature', '2m_dewpoint_temperature'],
target_months=[3, 4, 5],
area=[70, -11, 30, 120],
years=np.arange(1981, 2021),
folder='../Siberia_example/SEAS5/')
[3]:
retrieve.retrieve_ERA5(variables=['2m_temperature', '2m_dewpoint_temperature'],
target_months=[3, 4, 5],
area=[70, -11, 30, 120],
folder='../Siberia_example/ERA5/')
Preprocess¶
In the preprocessing step, we first merge all downloaded files into one netcdf file. Then the rest of the preprocessing depends on the definition of the extreme event. For example, for the UK case study, we want to extract the UK average precipitation while for the Siberian heatwave we will just used the defined area to spatially average over. For the MAM season, we still need to take the seasonal average, while for the UK we already have the average February precipitation.
Read the docs on preprocessing for more info.
Evaluate¶
The evaluation step is important to assess whether the forecasts are realistic and consistent to the observations. There are three statistical tests available through the UNSEEN R package. See the evaluation section for more info.
Case studies¶
So what can we learn from UNSEEN-open?
Have a look at the examples!