Launch in Binder ![]()
Siberian Heatwave¶
Prolonged heat events with an average temperature above 0 degrees over Siberia can have enormous impacts on the local environment, such as wildfires, invasion of pests and infrastructure failure, and on the global environment, through the release of greenhouse gasses during permafrost thawing.
The 2020 Siberian heatwave was a prolonged event that consistently broke monthly temperature the records. We show a gif of the monthly 2020 temperature rank within the observations from 1979-2020, see this section for details. - Rank 1 mean highest on record - Rank 2 means second highest - etc..
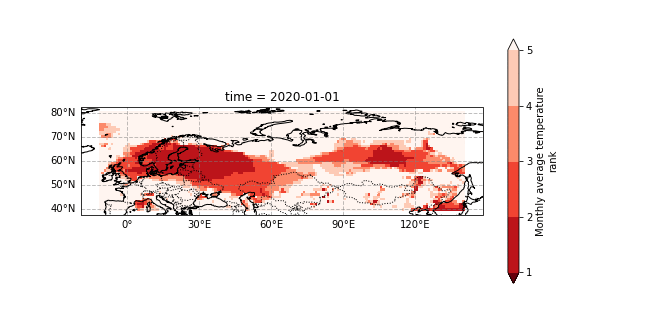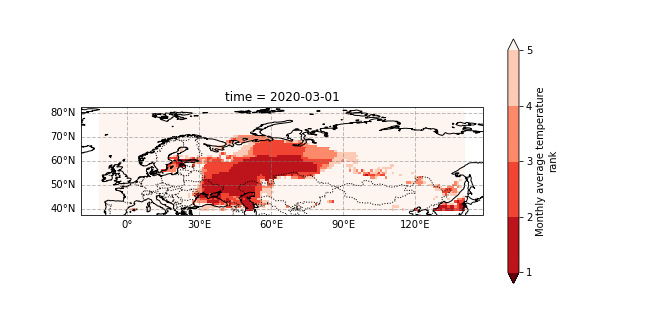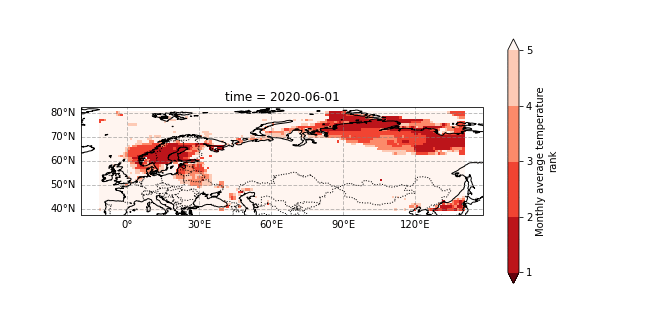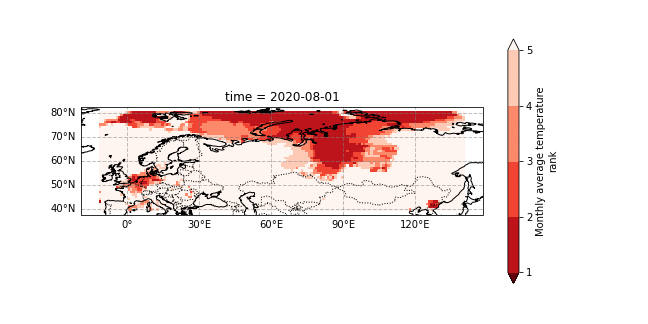
This attribution study by World Weather Attribution (WWA) has shown that the event was made much more likely (600x) because of human induced climate change but also that the event was a very rare event within our present climate.
Could such a thawing event be anticipated with UNSEEN?
With UNSEEN-open, we can assess whether extreme events like the Siberian heatwave have been forecasted already, i.e. whether we can anticipate such an event by exploiting all forecasts over the domain.
Retrieve data¶
The main functions to retrieve all forecasts (SEAS5) and reanalysis (ERA5) are retrieve_SEAS5 and retrieve_ERA5. We want to download 2m temperature, for the March-May target months over the Siberian domain. By default, the hindcast years of 1981-2016 are downloaded for SEAS5. We include the years 1981-2020. The folder indicates where the files will be stored, in this case outside of the UNSEEN-open repository, in a ‘Siberia_example’ directory. For more explanation, see
retrieve.
[1]:
import os
import sys
sys.path.insert(0, os.path.abspath('../../../'))
os.chdir(os.path.abspath('../../../'))
import src.cdsretrieve as retrieve
import src.preprocess as preprocess
import numpy as np
import xarray as xr
[2]:
retrieve.retrieve_SEAS5(
variables=['2m_temperature', '2m_dewpoint_temperature'],
target_months=[3, 4, 5],
area=[70, -11, 30, 120],
years=np.arange(1981, 2021),
folder='../Siberia_example/SEAS5/')
[3]:
retrieve.retrieve_ERA5(variables=['2m_temperature', '2m_dewpoint_temperature'],
target_months=[3, 4, 5],
area=[70, -11, 30, 120],
folder='../Siberia_example/ERA5/')
Preprocess¶
In the preprocessing step, we first merge all downloaded files into one xarray dataset, then take the spatial average over the domain and a temporal average over the MAM season. Read the docs on preprocessing for more info.
[4]:
SEAS5_Siberia = preprocess.merge_SEAS5(folder = '../Siberia_example/SEAS5/', target_months = [3,4,5])
Lead time: 02
1
12
And for ERA5:
[5]:
ERA5_Siberia = xr.open_mfdataset('../Siberia_example/ERA5/ERA5_????.nc',combine='by_coords')
Then we calculate the day-in-month weighted seasonal average:
[6]:
SEAS5_Siberia_weighted = preprocess.season_mean(SEAS5_Siberia, years = 39)
ERA5_Siberia_weighted = preprocess.season_mean(ERA5_Siberia, years = 42)
And we select the 2m temperature, and take the average over a further specified domain. This is an area-weighed average, since grid cell area decreases with latitude, see preprocess.
[8]:
area_weights = np.cos(np.deg2rad(SEAS5_Siberia_weighted.latitude))
SEAS5_Siberia_events_zoomed = (
SEAS5_Siberia_weighted['t2m'].sel( # Select 2 metre temperature
latitude=slice(70, 50), # Select the latitudes
longitude=slice(65, 120)). # Select the longitude
weighted(area_weights). # Apply the weights
mean(['longitude', 'latitude'])) # and take the spatial average
SEAS5_Siberia_events_zoomed_df = SEAS5_Siberia_events_zoomed.rename('t2m').to_dataframe() # weights remove the DataArray name, so I renamed the DaraArray after applying the weight.
In this workflow, ERA5 and SEAS5 are on the same grid and hence have the same weights:
[9]:
area_weights_ERA = np.cos(np.deg2rad(ERA5_Siberia_weighted.latitude))
area_weights_ERA == area_weights
[9]:
- latitude: 41
- True True True True True True True ... True True True True True True
array([ True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True]) - latitude(latitude)float3270.0 69.0 68.0 ... 32.0 31.0 30.0
- units :
- degrees_north
- long_name :
- latitude
array([70., 69., 68., 67., 66., 65., 64., 63., 62., 61., 60., 59., 58., 57., 56., 55., 54., 53., 52., 51., 50., 49., 48., 47., 46., 45., 44., 43., 42., 41., 40., 39., 38., 37., 36., 35., 34., 33., 32., 31., 30.], dtype=float32)
And here I take the spatial average 2m temperature for ERA5.
[42]:
ERA5_Siberia_events_zoomed = (
ERA5_Siberia_weighted['t2m'].sel( # Select 2 metre temperature
latitude=slice(70, 50), # Select the latitudes
longitude=slice(65, 120)). # Select the longitude
weighted(area_weights). # weights
mean(['longitude', 'latitude'])) # Take the average
ERA5_Siberia_events_zoomed_df = ERA5_Siberia_events_zoomed.rename('t2m').to_dataframe()
Evaluate¶
Note
From here onward we use R and not python!
We switch to R since we believe R has a better functionality in extreme value statistics.
Is the UNSEEN ensemble realistic?
[3]:
require(UNSEEN)
require(ggplot2)
require(ggpubr)
Loading required package: UNSEEN
Loading required package: ggplot2
Warning message:
“replacing previous import ‘vctrs::data_frame’ by ‘tibble::data_frame’ when loading ‘dplyr’”
Loading required package: ggpubr
Timeseries¶
We plot the timeseries of SEAS5 (UNSEEN) and ERA5 (OBS) for the the Siberian Heatwave.
[4]:
unseen_timeseries(
ensemble = SEAS5_Siberia_events_zoomed_df,
obs = ERA5_Siberia_events_zoomed[ERA5_Siberia_events_zoomed$year > 1981,],
ensemble_yname = "t2m",
ensemble_xname = "year",
obs_yname = "t2m",
obs_xname = "year",
ylab = "MAM Siberian temperature (C)") +
theme(text = element_text(size = 14)) #This is to increase the figure font
Warning message:
“Removed 2756 rows containing non-finite values (stat_boxplot).”
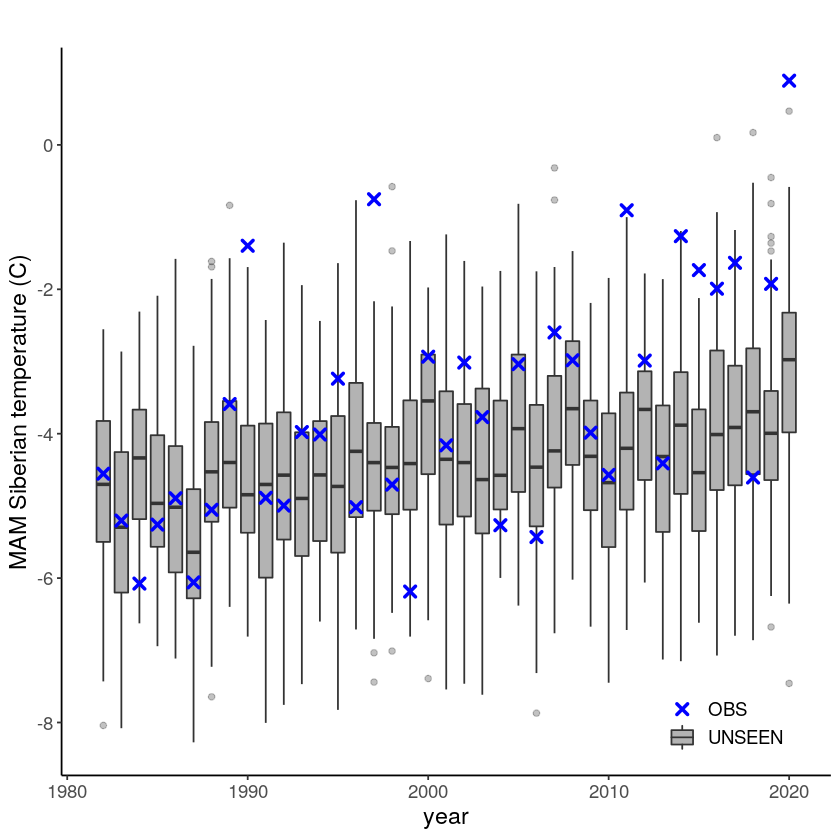
The timeseries consist of hindcast (years 1982-2016) and archived forecasts (years 2017-2020). The datasets are slightly different: the hindcasts contains 25 members whereas operational forecasts contain 51 members, the native resolution is different and the dataset from which the forecasts are initialized is different.
For the evaluation of the UNSEEN ensemble we want to only use the SEAS5 hindcasts for a consistent dataset. Note, 2017 is not used in either the hindcast nor the operational dataset, since it contains forecasts both initialized in 2016 (hindcast) and 2017 (forecast), see retrieve. We split SEAS5 into hindcast and operational forecasts:
[5]:
SEAS5_Siberia_events_zoomed_hindcast <- SEAS5_Siberia_events_zoomed_df[
SEAS5_Siberia_events_zoomed_df$year < 2017 &
SEAS5_Siberia_events_zoomed_df$number < 25,]
SEAS5_Siberia_events_zoomed_forecasts <- SEAS5_Siberia_events_zoomed_df[
SEAS5_Siberia_events_zoomed_df$year > 2017,]
And we select the same years for ERA5.
[6]:
ERA5_Siberia_events_zoomed_hindcast <- ERA5_Siberia_events_zoomed[
ERA5_Siberia_events_zoomed$year < 2017 &
ERA5_Siberia_events_zoomed$year > 1981,]
Which results in the following timeseries:
[7]:
unseen_timeseries(
ensemble = SEAS5_Siberia_events_zoomed_hindcast,
obs = ERA5_Siberia_events_zoomed_hindcast,
ensemble_yname = "t2m",
ensemble_xname = "year",
obs_yname = "t2m",
obs_xname = "year",
ylab = "MAM Siberian temperature (C)") +
theme(text = element_text(size = 14))
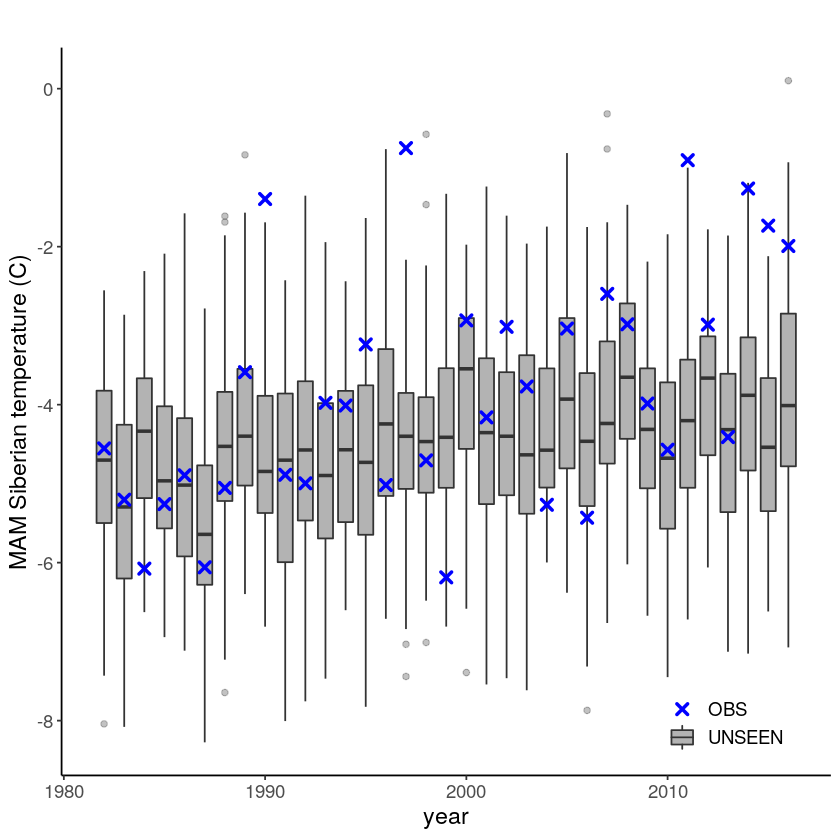
Evaluation tests¶
With the hindcast dataset we evaluate the independence, stability and fidelity. Here, we plot the results for the fidelity test, for more detail on the other tests see the evaluation section.
The fidelity test shows us how consistent the model simulations of UNSEEN (SEAS5) are with the observed (ERA5). The UNSEEN dataset is much larger than the observed – hence they cannot simply be compared. For example, what if we had faced a few more or a few less heatwaves purely by chance?
This would influence the observed mean, but not so much influence the UNSEEN ensemble because of the large data sample. Therefore we express the UNSEEN ensemble as a range of plausible means, for data samples of the same length as the observed. We do the same for higher order statistical moments.
[7]:
independence_test(
ensemble = SEAS5_Siberia_events_zoomed_hindcast,
n_lds = 3,
var_name = "t2m",
detrend = TRUE
) +
theme(text = element_text(size = 14))
Warning message:
“Removed 975 rows containing non-finite values (stat_ydensity).”
Warning message:
“Removed 975 rows containing non-finite values (stat_boxplot).”
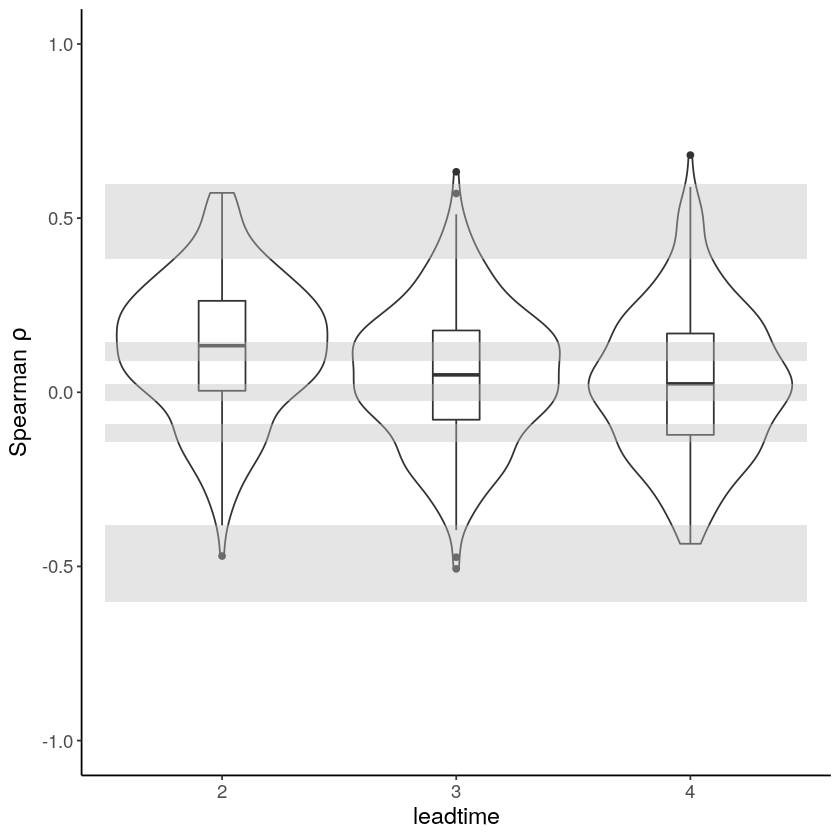
Is the model stable over leadtimes?
[8]:
stability_test(
ensemble = SEAS5_Siberia_events_zoomed_hindcast,
lab = 'MAM Siberian temperature',
var_name = 't2m'
)
Warning message:
“Removed 2 row(s) containing missing values (geom_path).”
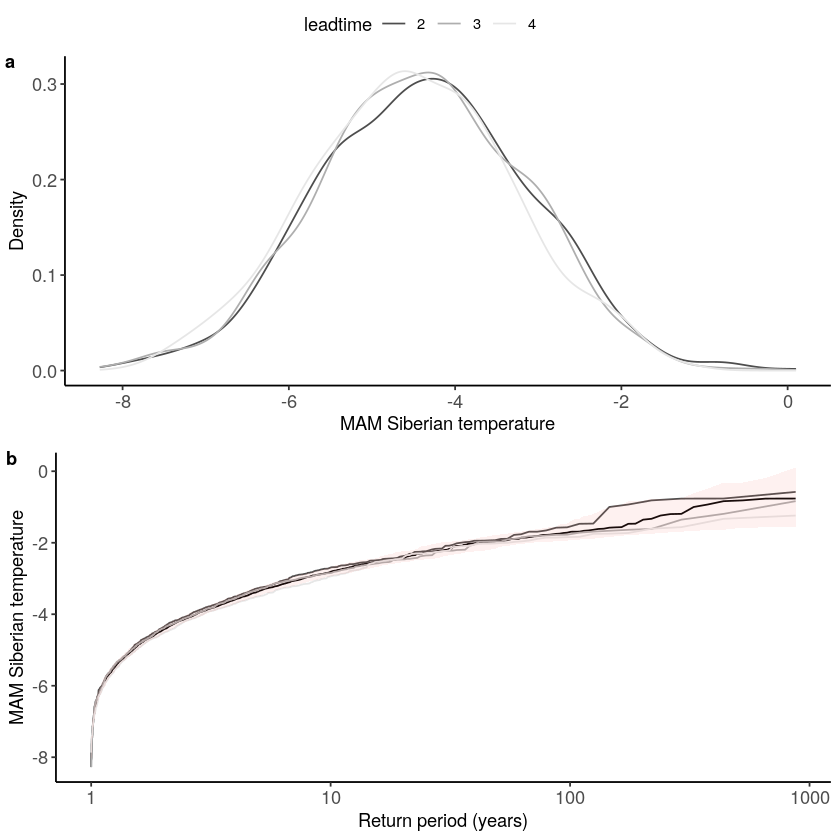
Is the model consistent with ERA5?
[9]:
fidelity_test(
obs = ERA5_Siberia_events_zoomed_hindcast$t2m,
ensemble = SEAS5_Siberia_events_zoomed_hindcast$t2m,
units = 'C',
biascor = FALSE,
fontsize = 14
)
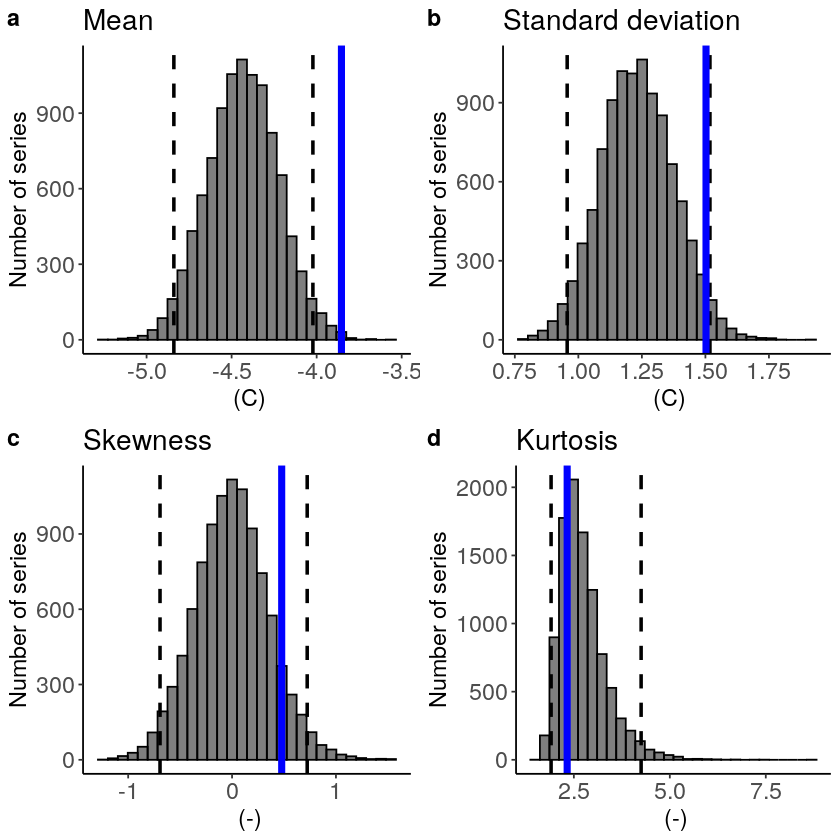
The fidelity test shows that the mean of the UNSEEN ensemble is too low compared to the observed – the blue line falls outside of the model range in a. To correct for this low bias, we can apply an additive bias correction, which only corrects the mean of the simulations.
Lets apply the additive biascor:
[11]:
obs <- ERA5_Siberia_events_zoomed_hindcast$t2m
ensemble <- SEAS5_Siberia_events_zoomed_hindcast$t2m
ensemble_biascor <- ensemble + (mean(obs) - mean(ensemble))
fidelity_test_biascor <- fidelity_test(
obs = obs,
ensemble = ensemble_biascor,
units = 'C',
ylab = '',
yticks = FALSE,
biascor = FALSE,
fontsize = 14
)
fidelity_test_biascor
# ggsave(fidelity_test_biascor,height = 90, width = 90, units = 'mm', filename = "graphs/Siberia_biascor.pdf")
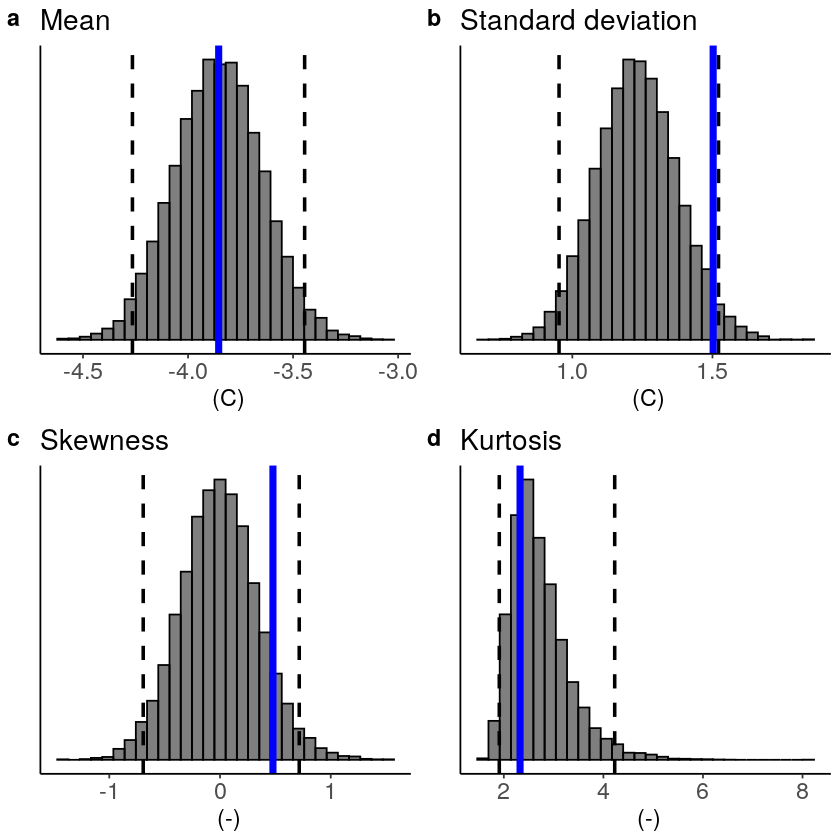
This shows us what we expected: the mean bias is corrected because the model simulations are shifted up (the blue line is still the same, the axis has just shifted along with the histogram), but the other statistical moments are the same.
Illustrate¶
So could thawing events (with an average temperature above 0 degrees) have been anticipated?
Here we create a bias adjusted dataframe:
[13]:
SEAS5_Siberia_events_zoomed_df_bc <- SEAS5_Siberia_events_zoomed_df
SEAS5_Siberia_events_zoomed_df_bc['t2m'] <- SEAS5_Siberia_events_zoomed_df_bc['t2m'] + (mean(obs) - mean(ensemble))
str(SEAS5_Siberia_events_zoomed_df_bc)
'data.frame': 5967 obs. of 4 variables:
$ year : int 1982 1982 1982 1982 1982 1982 1982 1982 1982 1982 ...
$ leadtime: int 2 2 2 2 2 2 2 2 2 2 ...
$ number : int 0 1 2 3 4 5 6 7 8 9 ...
$ t2m : num -3.16 -5.11 -3.64 -5.81 -2.93 ...
[14]:
unseen_timeseries(
ensemble = SEAS5_Siberia_events_zoomed_df_bc,
obs = ERA5_Siberia_events_zoomed[ERA5_Siberia_events_zoomed$year > 1981,],
ensemble_yname = "t2m",
ensemble_xname = "year",
obs_yname = "t2m",
obs_xname = "year",
ylab = "MAM Siberian temperature (C)") +
theme(text = element_text(size = 14)) + #This is to increase the figure font
geom_hline(yintercept = 0) #+
# ggsave(height = 90, width = 90, units = 'mm', filename = "graphs/Siberia_timeseries_biascor.pdf")
Warning message:
“Removed 2756 rows containing non-finite values (stat_boxplot).”
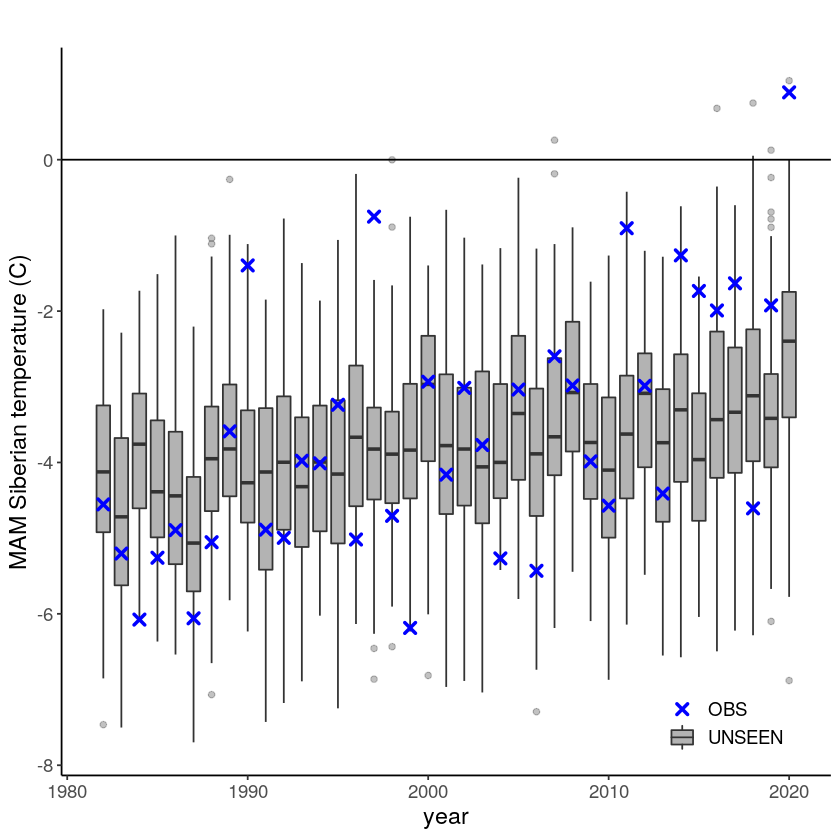
Applications:
With UNSEEN-open, we can: 1. Assess the drivers of the most severe events. The 2020 event seemed to be caused by a very anomalous Indian Ocean Dipole (IOD). What can we learn from the thawing events within UNSEEN? To what extent are these also driven by an anomalous IOD or are there other drivers of such severe heat events? 2. Perform nonstationary analysis in rare extremes, such as the 100-year event. There seems to be a trend over the hindcast period in the severe heatwaves. We can perform non-stationary analysis to estimate the change in the magnitude and frequency of the heatwaves and, if we find a change, we could explore the drivers of this change. 3. Evaluate forecasts. Since we are using seasonal forecasts in this setup, we could explore the forecast skill in simulating heatwaves over Siberia.